Workload-Aware Scheduling in Kubernetes 1.36
The API model and Gang Internals


Since Kubernetes v1.0, a single assumption has been baked into kube-scheduler: pods are the unit of scheduling. Each pod is an independent decision. The scheduler pops one pod off a priority queue, evaluates it against every node, filters, scores, picks a winner, binds it, and repeats. This is why Kubernetes scales to tens of thousands of nodes, and it’s why the scheduler is fast and simple.
That assumption works brilliantly for stateless services, where losing or delaying one pod doesn’t invalidate others. That model is fast, deterministic, and horizontally scalable. But if your job only makes progress when N pods come up together, as in distributed training or multi-pod inference, this is the missing primitive. And it is not a misconfiguration or scheduler tuning issue; it is by design.
For years, the ecosystem solved this outside the core scheduler. Volcano, Kueue, and the scheduler-plugins coscheduling project all provided some version of a PodGroup-like concept. They worked, but each spoke a different API dialect. That fragmentation forced higher-level controllers (e.g., Job, JobSet, LeaderWorkerSet, TrainJob, etc.) to choose a backend-specific gang-scheduling contract.
Kubernetes starts to change that. It introduces an in-tree API surface built around Workload, PodGroup, and Pod.spec.schedulingGroup. It is not trying to replace Kueue or Volcano. It provides the native gang primitive that those systems and built-in controllers can compose around.
Why pod-by-pod scheduling fails for distributed workloads
The kube-scheduler’s core path is meant to be simple: take one pod from the scheduling queue, evaluate it, and try to bind it. scheduler_one is the function name and the design statement.
The scheduling framework extension points are all built around a single Pod argument. Plugins can enrich the decision, but the framework’s basic unit remains a pod.
For stateless workloads, this is the right model. A Deployment with ten replicas usually does not care whether one replica starts now and another starts later. Each pod provides incremental value.
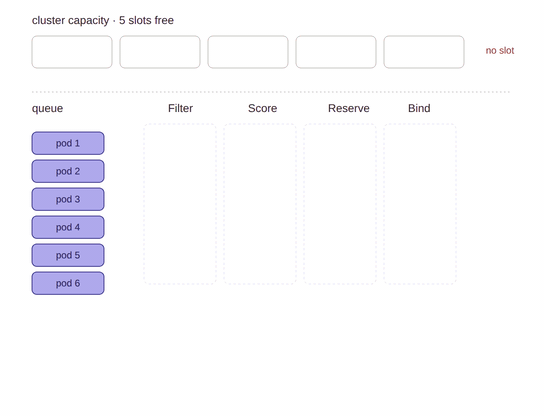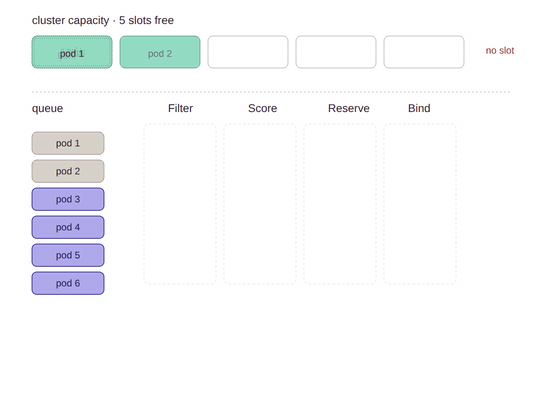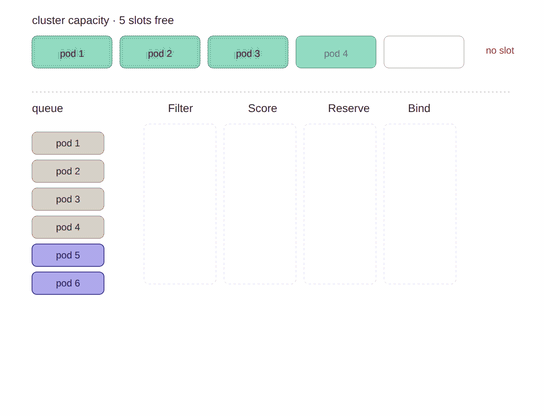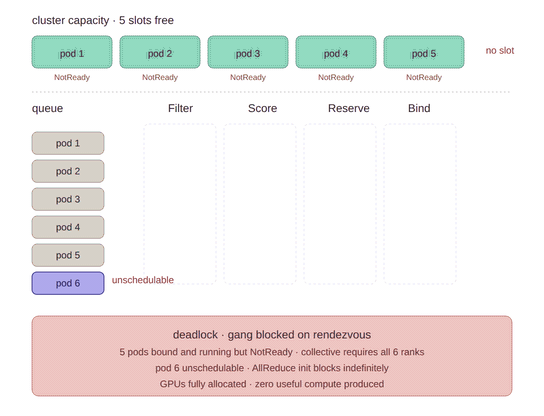
Gang workloads are different. In that world, scheduling five out of six pods is not 83% success. It is 0% useful progress plus 83% resource occupancy.
At a small scale, this looks like a six-pod job binding five pods and waiting for the sixth. At AI scale, it can look like a 512-GPU training run where 400 workers bind, 112 remain pending, and the 400 workers hold GPUs while doing no useful work. That is not a bin-packing bug. It is the scheduler committing too early because the API never told it that these pods were part of the same workload.
This is the API-level that Workload-Aware Scheduling targets.
The Shape of Workload-Aware Scheduling
Kubernetes model introduces a small set of composable primitives rather than a full batch scheduler.
The core behavior is straightforward:
A controller defines a workload-level scheduling policy
Workload.A runtime
PodGrouprepresents the group being scheduled.Pods reference that
PodGroup.The scheduler recognizes the group relationship.
For gang policy, the scheduler admits the group only when a quorum can be met.

This changes the commit point. Without gang scheduling, each pod can bind as soon as it fits on its own. With gang scheduling, the scheduler can delay binding until the group reaches minCount inside the scheduling attempt.
The Workload and PodGroup v1alpha2
The new model has three layers:
Workload: policy template that defines what scheduling policies should be applied to groups of Pods
PodGroup: a self-contained scheduling unit. It defines the group of Pods that should be scheduled together
Pod: references the PodGroup via
spec.schedulingGroup.podGroupName.
Workload: Only Policy
A Workload is a namespaced object that describes workload-level scheduling policy. It is not a controller. It does not create pods by itself. It is closer to a policy container that says: “when this workload creates PodGroups, here are the templates those PodGroups should use.”
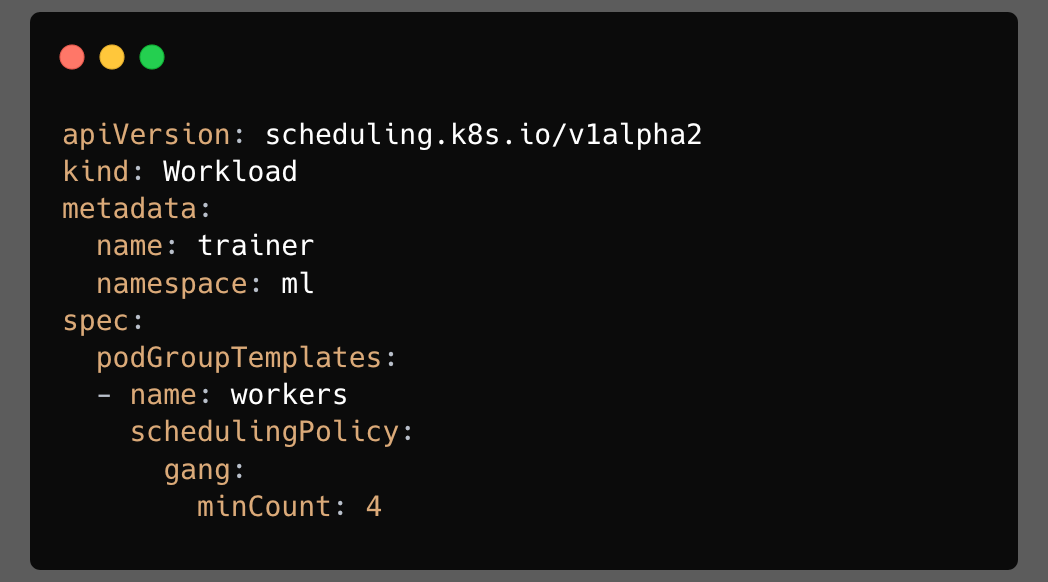
Each entry in podGroupTemplates is a named template. Controllers can create runtime PodGroups from those templates. A Workload can also carry spec.controllerRef, which points back to the logical controller object that owns the workload.
Basic vs gang scheduling
Every PodGroupTemplate carries one of two modes of schedulingPolicy that
determine how the scheduler treats the group’s pods. Picking the right one matters because it changes when pods commit to nodes and what happens when the cluster is too full to fit them all.
Basic
It gives the workload a group identity without changing the normal pod-at-a-time behavior. It is used when the pods are logically related but do not require a simultaneous start.
Why? It is useful plumbing. It lets controllers, status reporting, future preemption behavior, and future workload-aware features reason about related pods even if those pods do not need strict all-or-nothing admission.
Gang
It is the all-or-nothing policy. The minCount field defines the quorum: at least that many pods must be schedulable together for the group to be admitted. The value of gang.minCount is not only that it delays binding. It gives the scheduler a meaningful decision boundary: partial placement below quorum is not useful and should not consume resources.
PodGroup: The Runtime State
It is the runtime scheduling object. It is namespaced. It exists in the same namespace as the Workload and the pods it relates to.
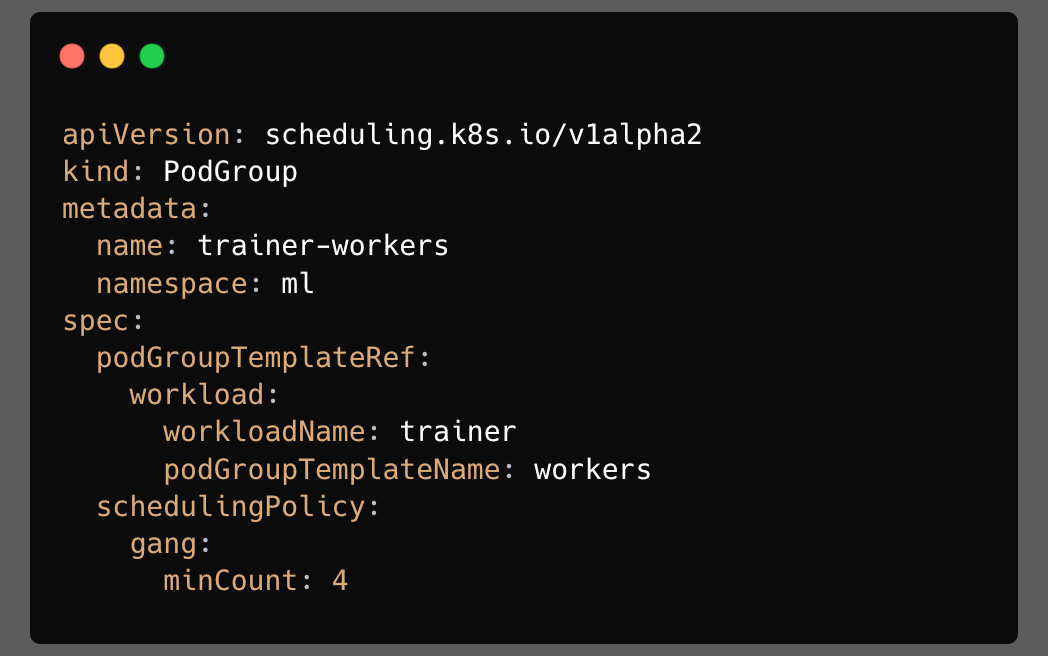
Once a controller creates a PodGroup from a template, the PodGroup must be self-contained. Scheduler decisions should not depend on a live lookup into a mutable template while a group is being scheduled.
The pod-side pointer
Pods opt into group scheduling by referencing a PodGroup:
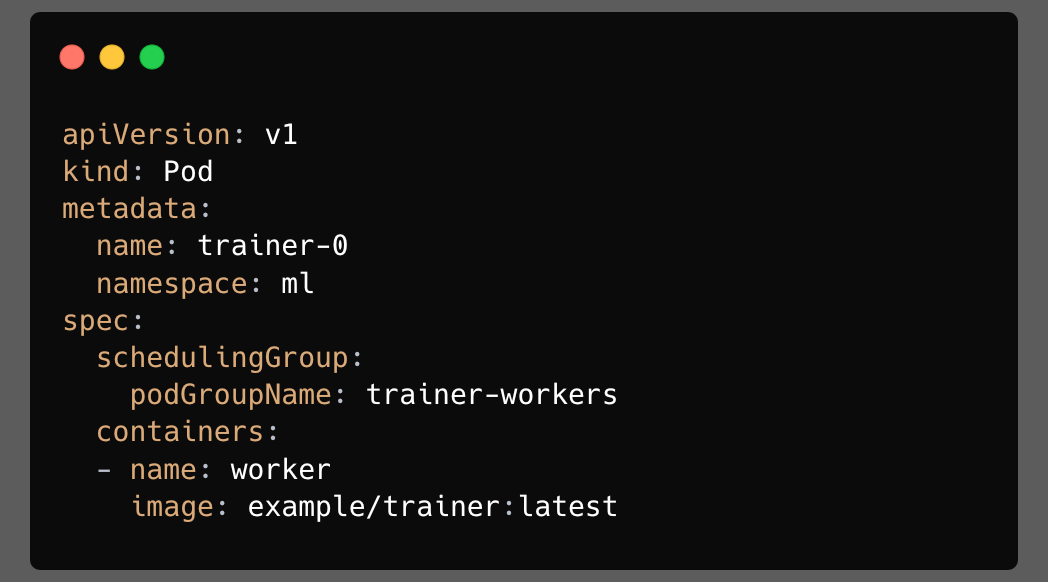
That field is immutable. A pod cannot move from one PodGroup to another after admission. Because if pods could change groups while waiting or during a scheduling cycle, the scheduler would need to handle a much more complex consistency model.
Why PodGroup is decoupled from Workload
The decoupling is one of the most important parts of the Kubernetes v1.36 design.
In the release v1.35, the design would embed all PodGroup runtime state directly inside the Workload. That would be simpler: one object, one place to look. Kubernetes avoids that shape for three reasons.
1. Object size
Large workloads can create many runtime scheduling groups. Embedding every runtime instance into a single Workload object would risk creating large objects and pushing against the limits of storing objects in etcd.
The decoupled model keeps the Workload small and moves the runtime state into separate PodGroup objects.
2. Status contention
Schedulers and controllers need to update the runtime status. If every PodGroup status update modified the parent Workload, a large workload would create a hot object. Decoupling allows each PodGroup to maintain its own status.
3. Ownership and cleanup
PodGroups are the natural lifetime boundary for related runtime resources, especially DRA claims. If a PodGroup owns generated resources, garbage collection can follow the PodGroup lifecycle.
Inside the gang-scheduling Plugin
The most important change in scheduler behavior is that a pod belonging to a PodGroup can cause the scheduler to process a group of pods. The flow is:
A pod enters the scheduling queue.
The scheduler sees
spec.schedulingGroup.podGroupName.The scheduler resolves the PodGroup.
The scheduler gathers relevant sibling pods.
The group is evaluated against a consistent cluster snapshot.
The gang policy decides whether binding can proceed.
Kubernetes is not replacing the scheduler with a batch scheduler. It is extending the scheduling path.
For gang scheduling, the two key extension points are:
PreEnqueue:keeps pods out of the active scheduling queue until the group exists and enough members are visible.Permit: holds assumed pods at the commit barrier until quorum is met.
PreEnqueue
PreEnqueue runs before a pod enters the active scheduling queue. If it fails, the pod does not consume a full scheduling cycle.
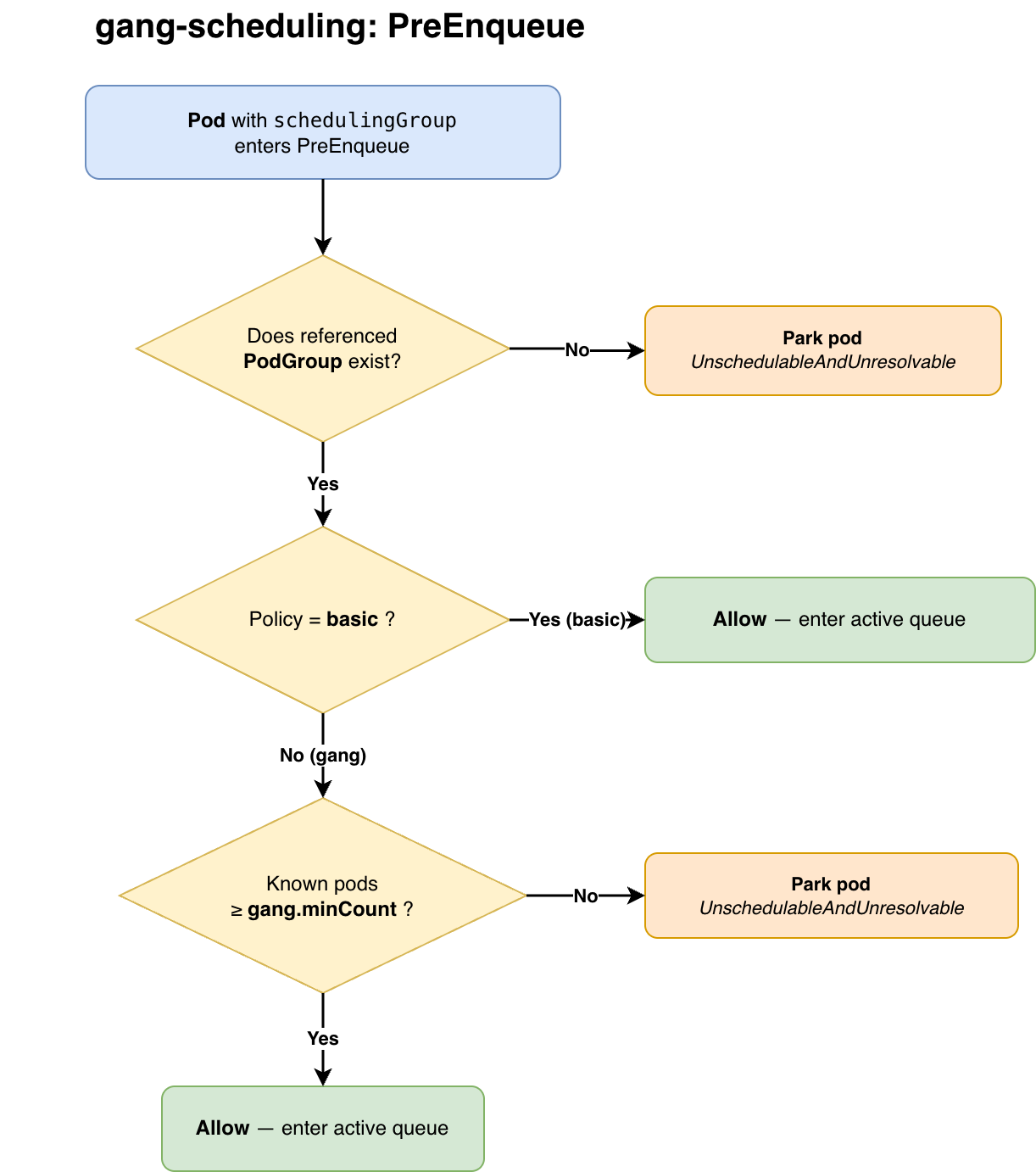
The decision tree is:
Does the referenced PodGroup exist?
If no, keep the pod parked.
Is the PodGroup policy `basic`?
If yes, let the pod through.
Is the policy `gang`?
Count known pods in the group.
If fewer than `minCount` are visible, keep the pod parked.
If at least `minCount` are visible, let the pod through.
The subtle part is how parked pods wake up. The plugin does not poll. It registers event hints, primarily:
- `Pod/Add`: a sibling pod appeared;
- `PodGroup/Add`: the referenced PodGroup appeared.
That event-driven behavior matters at scale. For a 512-pod gang, blind periodic retry would waste scheduler cycles while pods trickle in. Event hints wake only the pods that might be affected.
Permit
By the time a pod reaches Permit, the scheduler has already run filtering and scoring and selected a candidate node. The pod may be assumed in the scheduler’s internal cache, but it is not yet bound to the API erver.That makes Permit the right place to enforce the final gang barrier.
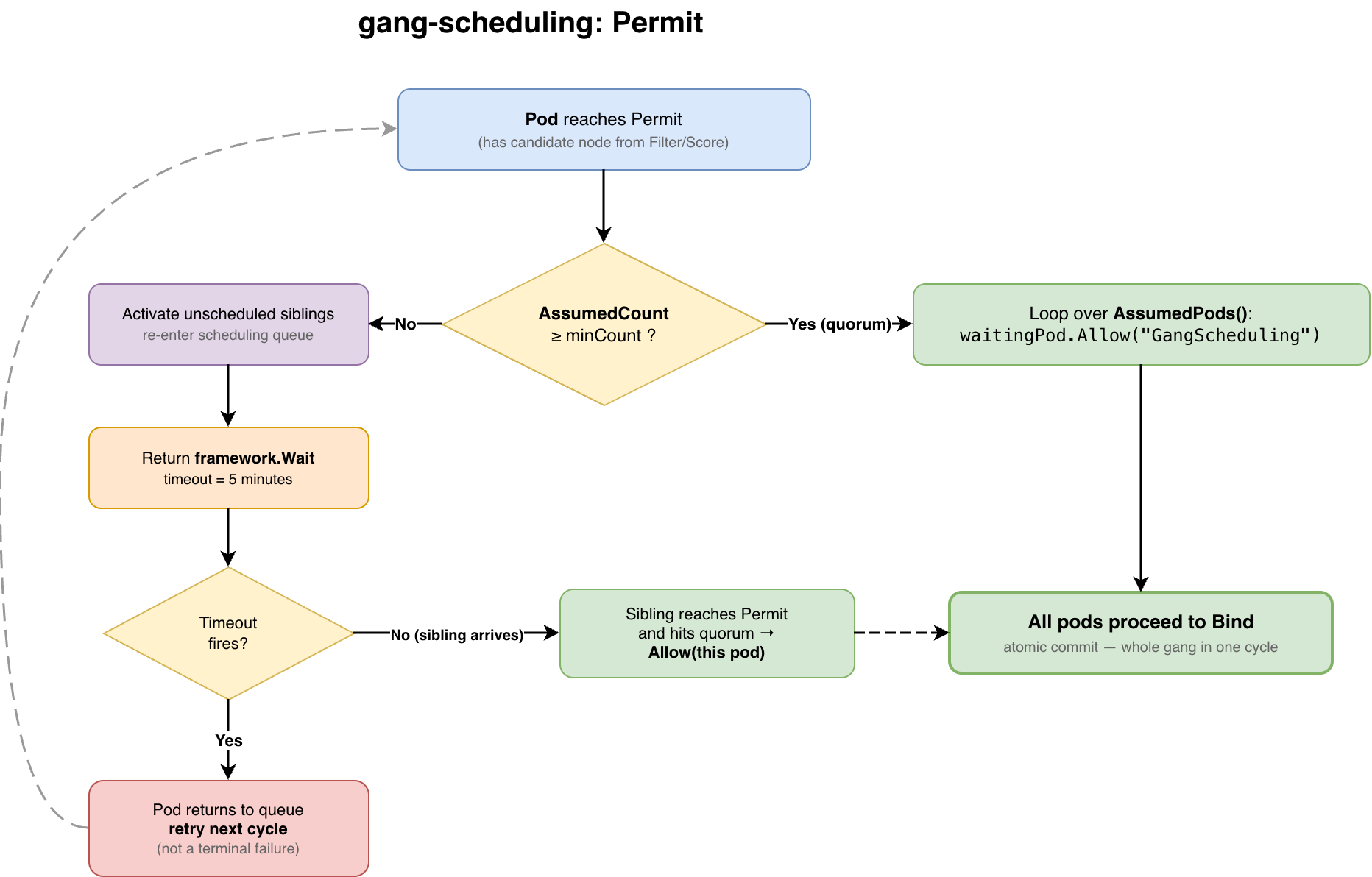
For a gang with `minCount: 4`, the behavior is:
Pod 1 reaches `Permit`.
The group has fewer than 4 assumed/schedulable members.
Pod 1 waits.
Pod 2 reaches `Permit`.
Still fewer than 4.
Pod 2 waits.
Pod 3 reaches `Permit`.
Still fewer than 4.
Pod 3 waits.
Pod 4 reaches `Permit`.
Quorum is now met.
The plugin allows the waiting siblings.
The group proceeds to the binding.
The key operation is “the allow loop” over waiting pods. There is no long-lived reservation protocol and no separate group controller doing a second commit.
Job controller integration
You can create Workload, PodGroup, and pods manually, but the Job controller integration made it easier.
With the WorkloadWithJob feature gate enabled, the Job controller can create the workload-aware objects for eligible Jobs. A Job is managed through this path when:
spec.parallelism > 1
spec.completionMode == Indexed
spec.completions == spec.parallelism (gang.minCount = Job.spec.parallelism)
The pod template does not already set spec.schedulingGroup
When those conditions hold, the controller creates:
`Workload` with a PodGroup template
`PodGroup` copied from that template
pods whose template references the PodGroup through `
pec.schedulingGroup.podGroupName`
Try it yourself
A demo repo includes runnable manifests for every scenario covered in this post, as well as the Job integration path, where the controller automatically creates the Workload and PodGroup for you.
Everything runs on a local kind cluster with the right feature gates. The repo includes a narrated verify.sh script that walks through each scenario and shows you exactly what to look for in the output.
In Part 2, we’ll go deeper into the additional features built on top of this foundation, including, WAS Preemption and Topology-Aware Scheduling (TAS) and how it interacts with workload-aware scheduling to place gangs within specific topology domains.